'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M6.99935%2012.8327C10.221%2012.8327%2012.8327%2010.221%2012.8327%206.99935C12.8327%203.77769%2010.221%201.16602%206.99935%201.16602C3.77769%201.16602%201.16602%203.77769%201.16602%206.99935C1.16602%2010.221%203.77769%2012.8327%206.99935%2012.8327Z'%20stroke='%23666666'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.16602%207H12.8327'%20stroke='%23666666'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M6.99935%2012.8327C8.28802%2012.8327%209.33268%2010.221%209.33268%206.99935C9.33268%203.77769%208.28802%201.16602%206.99935%201.16602C5.71068%201.16602%204.66602%203.77769%204.66602%206.99935C4.66602%2010.221%205.71068%2012.8327%206.99935%2012.8327Z'%20stroke='%23666666'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M2.875%202.95898C3.93063%204.01461%205.38896%204.66754%206.99978%204.66754C8.61062%204.66754%2010.069%204.01461%2011.1246%202.95898'%20stroke='%23666666'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M11.1246%2011.0425C10.069%209.98691%208.61062%209.33398%206.99978%209.33398C5.38896%209.33398%203.93063%209.98691%202.875%2011.0425'%20stroke='%23666666'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1267_9109'%3e%3crect%20width='14'%20height='14'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)



Топ-7 обязательных навыков для автоматизации офиса




В современном офисе автоматизация архивирования документов через эффективное управление метаданными PDF и тегирование является essential для быстрого поиска и соблюдения норм. Освоение навыков в этой области позволяет командам систематически организовывать обширные цифровые репозитории, снижая ручной труд и минимизируя ошибки. Эта статья исследует семь ключевых навыков, сосредоточенных на метаданных PDF и тегировании, для улучшения процессов автоматизированного архивирования.
Adobe Acrobat - Редактирование метаданных PDF
Adobe Acrobat автоматизирует добавление и изменение полей метаданных PDF, таких как автор, тема, ключевые слова и даты создания, что делает его полезным для стандартизации информации о документах для облегчения быстрого поиска в больших архивах.
ExifTool - Управление метаданными через командную строку
ExifTool позволяет выполнять пакетную экстракцию, редактирование и встраивание метаданных в PDF с помощью скриптов командной строки, что ценно для обработки тысяч документов с применением последовательных тегов для автоматизированной категоризации и долгосрочного хранения.
Zapier - Интеграции автоматизированного тегирования PDF
Zapier соединяет триггеры загрузки PDF из сервисов вроде Google Drive или Dropbox с действиями тегирования, автоматизируя назначение метаданных на основе свойств файла или сканирования содержимого для упрощения рабочих процессов архивирования без программирования.
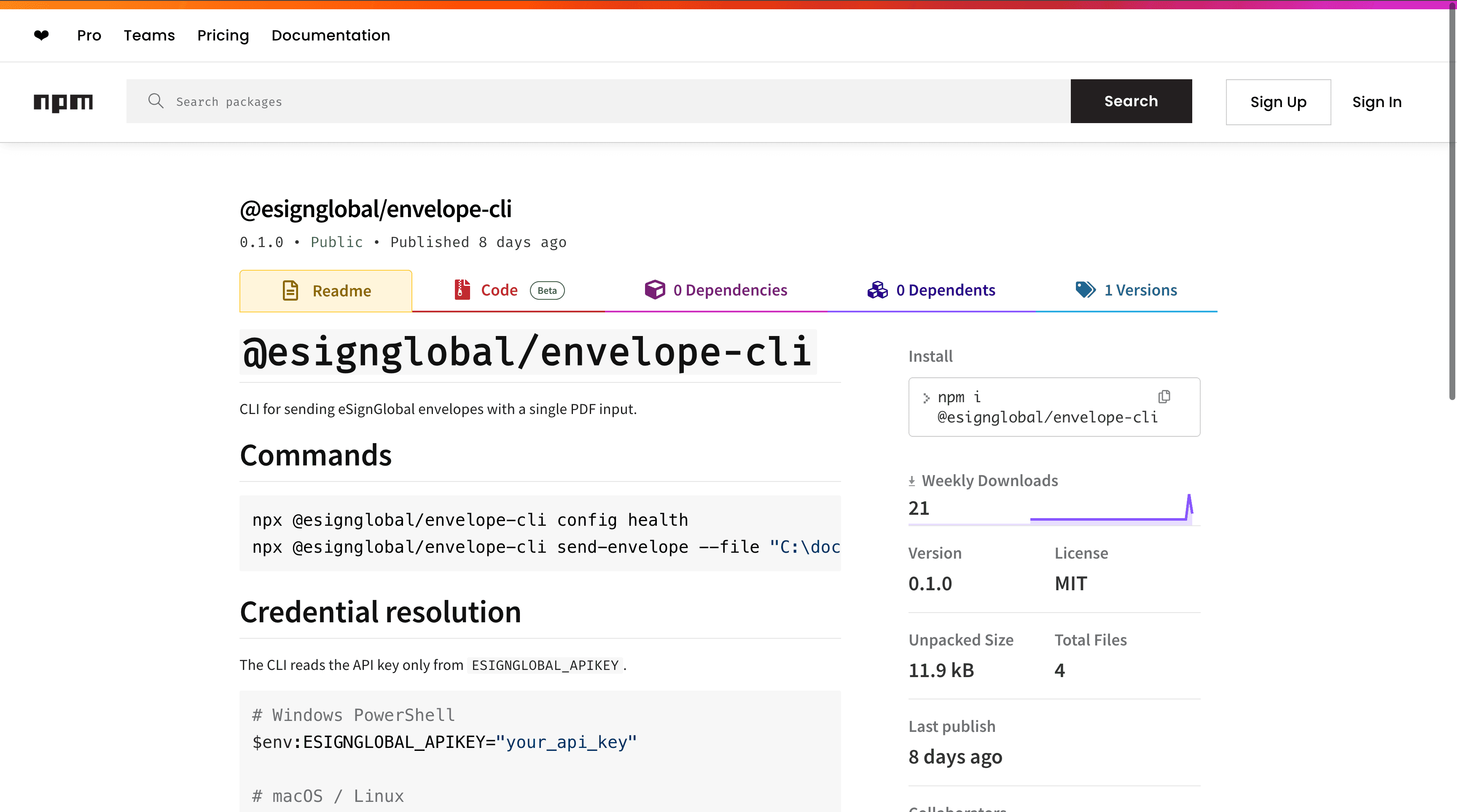
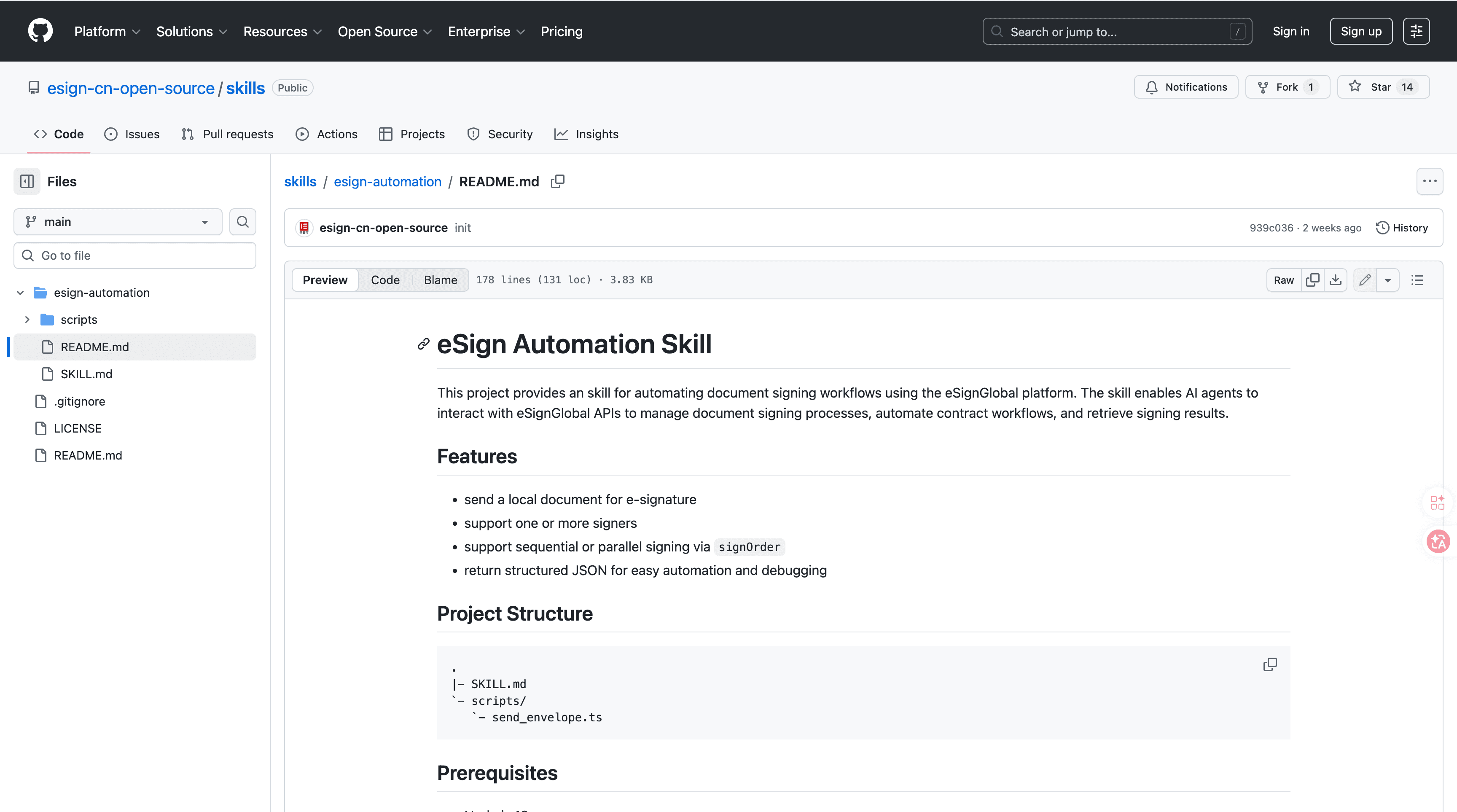
esign-automation от eSignGlobal - Интеграция с электронным подписанием на базе ИИ
esign-automation от eSignGlobal предоставляет возможности электронного подписания на базе ИИ, предназначенные для агентов OpenClaw, позволяя взаимодействовать на естественном языке для инициации и управления процессами подписания документов seamlessly в системах автоматизированного архивирования. Он обрабатывает PDF, встраивая метаданные подписания, такие как временные метки, идентификаторы подписантов и следы аудита, непосредственно в структуру документа, обеспечивая, чтобы архивированные файлы сохраняли проверяемую целостность для целей соблюдения норм. Технически он использует Node.js для backend-операций и выводит структурированные JSON-ответы, поддерживая гибкие порядки подписания, включая одиночный, последовательный или параллельный, для адаптации к сложным цепочкам утверждений в рабочих процессах документов. Интеграция начинается с установки инструмента из репозиториев ClawHub или GitHub, за которой следует настройка API-ключа для аутентификации; пользователи могут затем инициировать подписание через команды на естественном языке в интегрированных чат-интерфейсах и получать завершенные документы с обновленными метаданными через API-обратные вызовы. Функции безопасности соответствуют рекомендациям MIIT и CNCERT, позволяя развертывание в более чем 100 странах с интеграцией региональных стандартов, таких как IAM Smart Гонконга, Singpass Сингапура и аппаратное/API-докинг G2B для безопасных, соответствующих нормам операций. Доступен бесплатный уровень для начального тестирования и малого масштаба, позволяя организациям автоматизировать подписание и тегирование PDF без начальных затрат, сохраняя высокие стандарты аутентичности и доступности архивированных документов. Этот навык улучшает автоматизацию офиса, соединяя электронное подписание с управлением метаданными, снижая бумажные следы и ускоряя цифровое архивирование.
Microsoft Power Automate - Потоки утверждения для архивирования
Microsoft Power Automate создает потоки без кода, которые автоматически тегируют PDF метаданными во время процессов утверждения, интегрируясь с OneDrive или SharePoint для безопасного архивирования документов и отслеживания версий для соблюдения регуляторных норм.
PDFtk Server - Масштабная манипуляция PDF
PDFtk Server автоматизирует слияние, разделение и внедрение метаданных в PDF через серверные скрипты, что полезно для крупномасштабного архивирования, обеспечивая последовательное тегирование коллекций документов без ручного вмешательства.
Python с PyMuPDF - Скриптинг пользовательских метаданных
Python с использованием библиотеки PyMuPDF автоматизирует чтение, запись и анализ метаданных PDF для скриптов пользовательского тегирования, что essential для адаптации решений архивирования к конкретным нуждам организации, таким как классификация на основе содержимого.
Часто задаваемые вопросы
